简单理解 Java 垃圾收集器
了解垃圾回收 (GC) 在 Java 中的工作原理有什么好处?满足软件工程师的求知欲是一个合理的原因,而且,了解 GC 的工作原理可以帮助你编写更好的 Java 应用程序。
这是我非常个人和主观的意见,但我相信精通 GC 的人往往是更好的 Java 开发人员。如果你对 GC 过程感兴趣,那意味着你有开发特定规模的应用程序的经验。如果你仔细考虑过选择正确的 GC 算法,则意味着你完全了解你开发的应用程序的功能。当然,对于优秀的开发人员来说,这可能不是通用的标准。然而,当我说理解 GC 是成为一名优秀的 Java 开发人员的必要条件时,很少有人会反对。
这是“成为 Java GC 专家”系列文章的第一篇。这次我会介绍GC介绍,下一篇我会分析GC状态和GC调优例子。
在学习 GC 之前,你应该了解一个术语。该术语是 Stop-the-world。无论你选择哪种 GC 算法,都会发生 Stop-the-world。Stop-the-world意味着 JVM 正在停止应用程序运行以执行 GC。当 stop-the-world 发生时,除了 GC 所需的线程之外的每个线程都将停止它们的任务。被中断的任务只有在 GC 任务完成后才会恢复。
GC 调优通常意味着减少这种 Stop-the-world 的时间。
分代垃圾收集
Java 没有在程序代码中明确指定内存并将其删除。有些人将相关对象设置为 null 或使用 System.gc() 方法显式删除内存。设置为null没什么大不了的,但是调用System.gc()方法会严重影响系统性能,千万不要执行。
在Java中,由于开发者在程序代码中并没有显式地移除内存,垃圾收集器会发现不需要的(垃圾)对象并移除它们。这个垃圾收集器是基于以下两个假设创建的。(将它们称为假设或前提,而不是假设更正确。)
- 大多数对象很快就会变得无法访问。
- 从旧对象到新对象的引用只存在少量。
这些假设被称为weak generational hypothesis。所以为了保持这个假设的优势,在 HotSpot VM 中,它在物理上被分为两个——年轻代和老年代。
年轻代:大部分新创建的对象都位于这里。由于大多数对象很快就无法访问,因此许多对象在年轻代中创建,然后消失。当对象从该区域消失时,我们说发生了“minor GC ”。
老年代:从年轻代中没有变得不可达并幸存下来的对象被复制到这里。它通常比年轻代大。由于内存较大,GC 发生的频率低于年轻代。当对象从老年代消失时,我们说发生了“ major GC ”(或“ full GC ”)。
让我们用图表来看看。
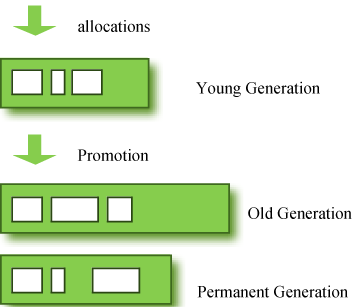
图 1:GC 区域和数据流。
上图中的永久代也称为“方法区”,它存储类或内部字符串。所以,这个区域绝对不是让老年代存活下来的物体永久存在的。这个区域可能会发生GC。此处发生的 GC 仍被视为 major GC 。
可能有人会疑惑:
如果老年代的对象需要引用年轻代的对象怎么办?
为了处理这些情况,老年代有一个叫做 card table 的东西,它是一个512 字节的块。每当老年代的对象引用年轻代的对象时,都会记录在这张表中。对年轻代执行GC时,只查找这张卡片表来判断它是否是GC的主题,而不是检查老年代所有对象的引用。这个卡表是用写屏障*管理的。这个写屏障是一种可以为 minor GC 提供更快性能的设备。尽管因此会产生一些开销,但总体 GC 时间减少了。
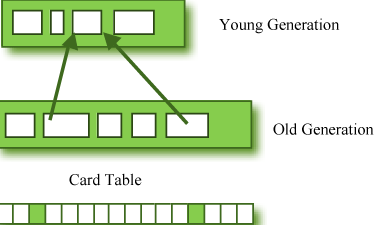
图 2:卡片表结构。
年轻一代的组成
为了理解GC,让我们了解一下年轻代,第一次创建对象的地方。年轻代分为3个空间。
- 一Eden 空间
- 两个Survivor 空间
总共有3个空间,其中两个是Survivor空间。每个空间的执行过程顺序如下:
- 大多数新创建的对象都位于 Eden 空间中。
- 在 Eden 空间中进行一次 GC 后,将幸存的对象移动到 Survivor 空间之一。
- 在 Eden 空间进行一次 GC 后,对象被堆积到 Survivor 空间中,该空间已经存在其他幸存的对象。
- 一旦 Survivor 空间已满,幸存的对象就会移动到另一个 Survivor 空间。然后,已满的 Survivor 空间将变为完全没有数据的状态。
- 在重复多次的这些步骤中幸存下来的对象被移动到老年代。
通过检查这些步骤可以看到,幸存者空间之一必须保持为空。如果数据在两个 Survivor 空间中都存在,或者两个空间的使用量都为 0,则将其视为你的系统出现问题的标志。
数据通过minor GC堆积到老年代的过程如下图所示:
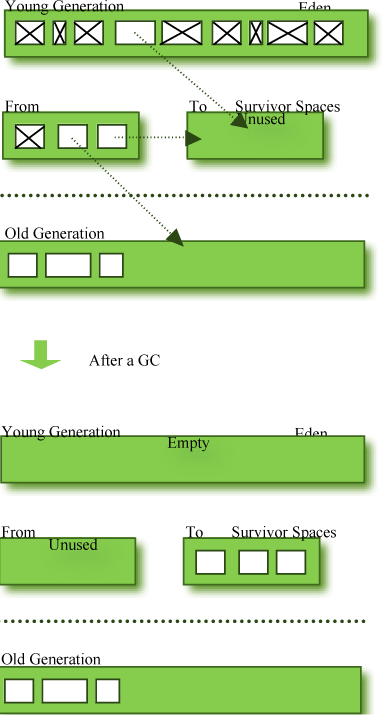
图 3:GC 之前和之后。
请注意,在 HotSpot VM 中,使用了两种技术来实现更快的内存分配。一种称为“bump-the-pointer”,另一种称为“ TLAB(线程本地分配缓冲区)”。
Bump-the-pointer 技术跟踪分配给 Eden 空间的最后一个对象。该物体将位于伊甸园空间的顶部。如果之后创建了一个对象,它只会检查对象的大小是否适合 Eden 空间。如果所述对象看起来正确,它将被放置在伊甸园空间中,而新对象将放在最上面。因此,当创建新对象时,只需要检查最后添加的对象,这样可以更快地分配内存。但是,如果我们考虑多线程环境,情况就不同了。为了将多个线程使用的对象保存在 Eden 空间中用于 Thread-Safe,不可避免地会发生锁,并且由于锁争用而导致性能下降。
TLABs 是 HotSpot VM 中此问题的解决方案。这允许每个线程拥有一小部分对应于自己共享的 Eden 空间。由于每个线程只能访问自己的 TLAB,因此即使是指针碰撞技术也允许在没有锁定的情况下进行内存分配。
这是对年轻代 GC 的快速概览。你不一定要记住我刚刚提到的两种技术。你不会因为不认识他们而入狱。但是请记住,在Eden空间首先创建对象之后,通过Survivor空间将长期存活的对象移动到老年代。
老年代GC
老年代基本上是在数据满的时候进行一次GC。执行过程因GC类型而异,所以如果你了解不同类型的GC会更容易理解。
根据 JDK 7,有 5 种 GC 类型。
- 串行气相色谱
- 并行GC
- Parallel Old GC (Parallel Compacting GC)
- 并发标记和清除 GC(或“CMS”)
- 垃圾优先 (G1) GC
其中,串行 GC 不得用于正在运行的服务器上。这种 GC 类型是在台式计算机上只有一个 CPU 核心时创建的。使用此串行 GC 将显着降低应用程序性能。
现在让我们了解每种 GC 类型。
Serial GC (-XX:+UseSerialGC)
年轻代中的 GC 使用我们在上一段中解释的类型。老年代的 GC 使用了一种叫做“ mark-sweep-compact ”的算法。
- 该算法的第一步是标记老年代幸存的对象。
- 然后,它从前面检查堆,只留下幸存的堆(扫描)。
- 在最后一步,它从前面用对象填充堆,使对象连续堆积,并将堆分成两部分:有对象的部分和没有对象的部分(紧凑)。
串行GC适用于小内存和少量CPU内核。
Parallel GC (-XX:+UseParallelGC)
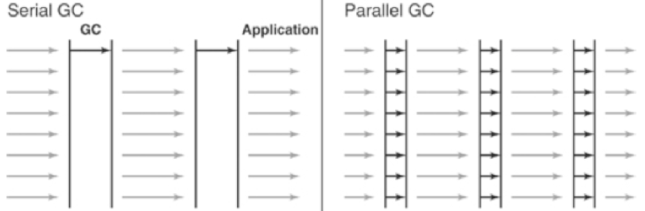
图 4:串行 GC 和并行 GC 之间的区别。
从图中可以很容易看出串行GC和并行GC的区别。串行 GC 仅使用一个线程来处理 GC,而并行 GC 使用多个线程来处理 GC,因此速度更快。当有足够的内存和大量内核时,此 GC 很有用。它也被称为“吞吐量 GC”。
Parallel Old GC(-XX:+UseParallelOldGC)
自 JDK 5 更新以来,支持 Parallel Old GC。与并行 GC 相比,唯一的区别是老年代的 GC 算法。它经历了三个步骤:标记 - 摘要 - 压缩。汇总步骤针对 GC 先前执行过的区域分别识别幸存对象,因此不同于标记-扫描-压缩算法的扫描步骤。它经历了更复杂的步骤。
CMS GC (-XX:+UseConcMarkSweepGC)
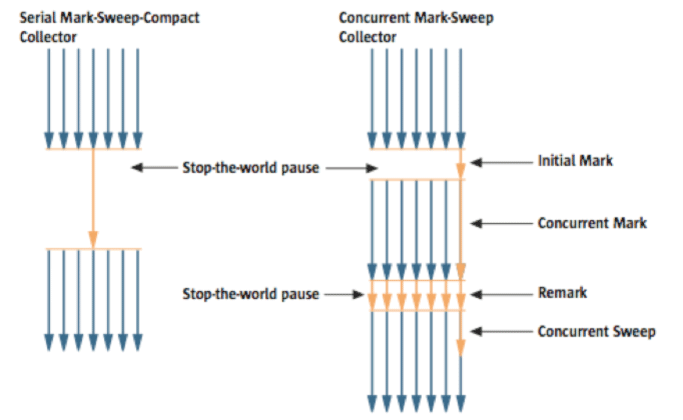
图 5:串行 GC 和 CMS GC。
从图中可以看出,Concurrent Mark-Sweep GC 比我迄今为止解释的任何其他 GC 类型都要复杂得多。早期的初始标记步骤很简单。在最接近类加载器的对象中搜索幸存的对象。所以,暂停时间很短。在并发标记步骤中,对刚刚确认的幸存对象所引用的对象进行跟踪和检查。这一步的不同之处在于它在处理其他线程的同时进行。在remark步骤中,检查并发标记步骤中新添加或停止引用的对象。最后,在并发扫描中步骤,垃圾收集程序发生。在其他线程仍在处理中时执行垃圾收集。由于这种GC类型以这种方式执行,因此GC的暂停时间非常短。CMS GC 也称为低延迟 GC,在所有应用程序的响应时间至关重要时使用。
虽然这种 GC 类型具有停止世界时间短的优点,但它也有以下缺点。
- 它比其他 GC 类型使用更多的内存和 CPU。
- 默认情况下不提供压缩步骤。
在使用这种类型之前,你需要仔细检查。此外,如果由于内存碎片很多而需要执行压缩任务,则 stop-the-world 时间可能比任何其他 GC 类型都长。你需要检查执行压缩任务的频率和时间。
G1 GC
最后,让我们了解一下垃圾优先(G1)GC。

图 6:G1 GC 的布局。
如果你想了解 G1 GC,忘记你所知道的关于年轻代和年老代的一切。如图所示,每个网格分配一个对象,然后执行一次GC。然后,一旦一个区域已满,将对象分配到另一个区域,然后执行 GC。数据从年轻代三个空间移动到老年代的步骤在这种GC类型中是找不到的。创建这种类型是为了取代 CMS GC,从长远来看,它会引起很多问题和抱怨。G1 GC 的最大优势在于其性能。它比我们目前讨论的任何其他 GC 类型都快。
参考文档:
https://www.cubrid.org/blog/3826410